※ この記事にはアフィリエイトリンクが含まれます

データベースを運用していると、意図せず重複データが発生することがあります。例えば、ユーザーが同じデータを二重に登録してしまったり、バッチ処理のミスで同じレコードが複数挿入されてしまったりするケースです。
重複データがあると、検索結果の精度が下がるだけでなく、データの一貫性が損なわれる可能性があります。
本記事では、PostgreSQLで重複データを確認し、安全に削除する方法について解説します。
これから本格的にプログラミングを学びたい方へ
もしあなたがSQLのスキルだけでなく、「正規表現だけじゃなく、もっと本格的にプログラミングを学びたい」と思っているなら、実務レベルでのスキルが身につく「RareTECH」という学習サービスがおすすめです。
 なんくる
なんくる本気でやってみたい。でも何から始めたらいいか分からない。そんなときこそ、信頼できる学習環境に頼っていいんです。一人で悩む時間を、実務レベルの力に変えられます!
少しでも気になった方は、まずは無料カウンセリングで話を聞いてみるのがおすすめです。
重複データの確認方法
重複データを削除する前に、まずはどのデータが重複しているのかを確認する必要があります。PostgreSQLでは、GROUP BY や COUNT(*) を使用して、特定のカラムに重複がないかをチェックできます。
重複データの検索
例えば、users テーブルに email カラムがあり、同じ email が複数回登録されているかを確認したい場合、以下のSQLを実行します。
SELECT email, COUNT(*)
FROM users
GROUP BY email
HAVING COUNT(*) > 1;このクエリの解説
GROUP BY emailによって、emailごとにデータをグループ化します。COUNT(*)によって、それぞれのemailの出現回数をカウントします。HAVING COUNT(*) > 1によって、2件以上存在する(=重複している)データのみを抽出します。
実行結果の例

この結果から、user@example.com は2件、test@example.com は3件の重複があることがわかります。
重複データの詳細を確認
重複しているデータの詳細(IDや登録日時など)を確認したい場合、JOIN を利用すると便利です。
SELECT u.*
FROM users u
JOIN (
SELECT email
FROM users
GROUP BY email
HAVING COUNT(*) > 1
) dup ON u.email = dup.email
ORDER BY u.email, u.id;このクエリでは、重複している email のみを対象に users テーブルを結合することで、詳細な情報を取得できます。
実行結果の例
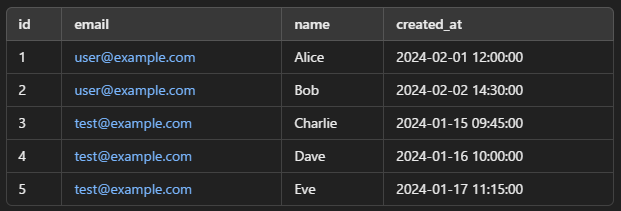
この結果から、どの id のデータが重複しているのか、登録日時の順番などがわかるため、削除対象を決める際に役立ちます。
DISTINCT ON を使って重複を回避
DISTINCT ON を使うと、特定のカラムに基づいて一意なレコードのみを取得できます。例えば、各 email ごとに最新のレコードだけを取得する場合、次のSQLを実行します。
SELECT DISTINCT ON (email) *
FROM users
ORDER BY email, created_at DESC;この方法を使えば、削除する前に「どのデータを残すべきか」を考慮できます。
重複データを削除する方法
重複データの確認ができたら、不要なデータを削除する方法を考えます。PostgreSQLでは、重複データの削除方法として以下の3つの方法が考えられます。
DELETEを使用する方法(ROW_NUMBER()を活用)DISTINCT ONを使って新しいテーブルを作成する方法WITH句を使って一時テーブルを利用する方法
それぞれの方法について詳しく見ていきましょう。
DELETEを使う方法
DELETE を使用する場合、重複データのうち「どれを残し、どれを削除するか」を決める必要があります。ROW_NUMBER() を使うと、各グループ内で削除対象を特定できます。
例:email カラムの重複を削除する
email ごとに id の小さい(または古い)データを削除する場合、以下のように ROW_NUMBER() を使います。
DELETE FROM users
WHERE id IN (
SELECT id FROM (
SELECT id, ROW_NUMBER() OVER (PARTITION BY email ORDER BY id ASC) AS row_num
FROM users
) t
WHERE t.row_num > 1
);クエリの解説
PARTITION BY emailによって、emailごとにデータをグループ化。ORDER BY id ASCでidが小さい順に並べ、ROW_NUMBER()を割り振る。row_num > 1のデータをDELETEの対象として削除。
この方法では、id の最も小さいデータだけが残ります。
DISTINCT ON を使って新しいテーブルを作成する
データ量が多い場合、一度に大量の DELETE を実行するとパフォーマンスに影響することがあります。その場合、新しいテーブルを作成し、重複を取り除いたデータを挿入する方法も有効です。
手順
DISTINCT ONを使って、重複のないデータを抽出し、新しいテーブルを作成。- 元のテーブルを削除し、新しいテーブルを置き換える。
CREATE TABLE users_new AS
SELECT DISTINCT ON (email) *
FROM users
ORDER BY email, id DESC;
DROP TABLE users;
ALTER TABLE users_new RENAME TO users;クエリの解説
DISTINCT ON (email)を使うと、emailごとに最初に出現する1件のみを取得。ORDER BY email, id DESCにより、idが大きい(最新の)データを優先的に保持。users_newにデータを保存し、usersを置き換える。
この方法は、大量のデータがある場合に高速に重複を削除できます。
WITH 句を使った一時テーブルを利用する
削除前に対象データを確認したい場合、一時テーブル (WITH 句) を活用すると便利です。
WITH duplicate_ids AS (
SELECT id FROM (
SELECT id, ROW_NUMBER() OVER (PARTITION BY email ORDER BY id ASC) AS row_num
FROM users
) t
WHERE t.row_num > 1
)
DELETE FROM users
WHERE id IN (SELECT id FROM duplicate_ids);この方法を使うと、一時テーブル duplicate_ids を事前に確認でき、誤削除を防ぐことができます。
まとめ
本記事では、PostgreSQLで重複データを削除する方法について解説しました。データベースの一貫性を保つために、重複データを適切に管理することは非常に重要です。
データの重複は、システムの設計や運用のミスによって発生することがあります。
今回紹介した方法を活用し、定期的にデータをチェック・クリーニングすることで、データベースのパフォーマンスと整合性を維持しましょう!
PostgreSQLは、現場でも広く使われている信頼性の高いデータベースです。もしこれから本格的に学び、実務で通用する力をつけたい方には、RareTECHをチェックしてみてください。実案件ベースのカリキュラムで、あなたのスキルを次のステージへ引き上げてくれるはずです。
 なんくる
なんくる「本当にエンジニアとしてやっていけるか不安…」という方も、実践的な開発に関わることで、転職後の働き方を事前に体感できますよ。
実務で使えるDBスキルとともに、プログラミングスキルをちゃんと身につけたいなら、
RareTECHの無料カウンセリングで、学ぶ目的やゴールをプロと一緒に明確にしてみましょう。独学では得られない「実践的な成長の道筋」が見えてきます。

もしこの内容を通して、PostgreSQLについてさらに理解を深めたいと感じられたなら、信頼できる講座や書籍を紹介した別記事をご覧いただくのも良いかと思います。ご自身の学びに、きっとお役立ていただけるはずです。









コメント