※ この記事にはアフィリエイトリンクが含まれます

データベースを使用して大量のデータを扱う際、特定の条件でデータをグループ化して集計する操作は非常に重要です。PostgreSQLをはじめとする多くのRDBMSでは、この操作を効率的に行うためにGROUP BY句が提供されています。
GROUP BY句を使用すると、共通の値を持つ行を1つのグループとしてまとめ、それぞれのグループに対して集計関数(SUM、AVG、COUNTなど)を適用することができます。これにより、単なるデータの取得にとどまらず、より深い分析やレポート作成が可能になります。
本記事では、PostgreSQLにおけるGROUP BY句の基本的な使い方をはじめ、よく使われる集計関数との組み合わせ方や注意点、さらに応用的な使い方について詳しく解説します。初心者から中級者まで、GROUP BY句の理解を深めたい方に役立つ内容を目指しますので、ぜひ参考にしてください!
これから本格的にプログラミングを学びたい方へ
もしあなたがSQLのスキルだけでなく、「正規表現だけじゃなく、もっと本格的にプログラミングを学びたい」と思っているなら、実務レベルでのスキルが身につく「RareTECH」という学習サービスがおすすめです。
 なんくる
なんくる本気でやってみたい。でも何から始めたらいいか分からない。そんなときこそ、信頼できる学習環境に頼っていいんです。一人で悩む時間を、実務レベルの力に変えられます!
少しでも気になった方は、まずは無料カウンセリングで話を聞いてみるのがおすすめです。
GROUP BY句の基本的な使い方
GROUP BY句は、データを特定の基準でグループ化し、そのグループごとに集計や分析を行う際に使用されます。このセクションでは、GROUP BY句の基本構文とその動作を解説します。
基本構文
SELECT カラム1, 集計関数(カラム2)
FROM テーブル名
GROUP BY カラム1;- カラム1:データをグループ化する基準となる列
- 集計関数(カラム2):グループごとに計算を行う関数(例:SUM、COUNT、AVGなど)
グループ化の例として、次のような売上データを持つテーブル sales を基に説明します。
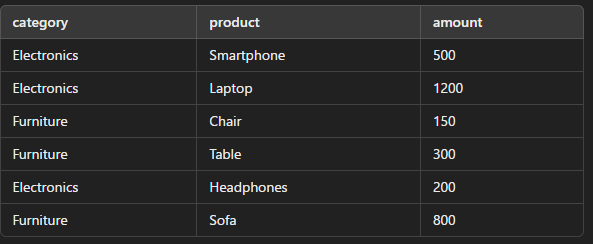
category 列でデータをグループ化し、各カテゴリの合計売上(amount)を計算します。
SELECT category, SUM(amount) AS total_sales
FROM sales
GROUP BY category;このクエリを実行すると、次のような結果が得られます。

この例では、GROUP BY category を指定することで、category 列の値ごとに行がグループ化され、SUM(amount) によって各グループの売上が計算されています。
GROUP BY句と集計関数
GROUP BY句は、集計関数と組み合わせることで、グループごとの統計情報を簡単に取得できます。PostgreSQLでは、以下のような集計関数がよく使用されます。
よく使われる集計関数
- SUM()
指定した列の合計値を計算 - AVG()
指定した列の平均値を計算 - COUNT()
指定した列の値の数をカウント - MIN()
指定した列の最小値を取得 - MAX()
指定した列の最大値を取得
これらの関数をGROUP BY句と組み合わせると、各グループごとの集計結果を取得できます。
以下の例では、sales テーブルのデータを用いて各カテゴリの統計情報を取得します。
グループごとの売上合計と件数
SELECT category, SUM(amount) AS total_sales, COUNT(*) AS product_count
FROM sales
GROUP BY category;実行結果

グループごとの最小値と最大値
SELECT category, MIN(amount) AS min_sales, MAX(amount) AS max_sales
FROM sales
GROUP BY category;実行結果

注意点
NULLの扱い:集計関数は通常、NULL値を無視します。ただし、COUNT(*)はNULLも含めてカウントします。
GROUP BY句に含まれない列の使用:SELECT句で使用できるのは、GROUP BY句で指定された列または集計関数を使った列だけです。
これらの基本を理解すれば、GROUP BY句を使ったデータ分析がより効果的に行えます。
GROUP BY句の注意点
GROUP BY句はデータ分析において強力なツールですが、正しく使用するためにはいくつかの注意点を理解しておく必要があります。ここでは、GROUP BY句を使用する際に気をつけるべきポイントを解説します。
GROUP BY句に含まれないカラムをSELECTで指定するとエラーが発生
PostgreSQLでは、GROUP BY句で指定していない列をSELECT句で参照することはできません。このルールは、GROUP BY句を使うことで行がグループ化されるため、非集約列の値が一意ではなくなる可能性があるためです。
エラー例
SELECT category, product, SUM(amount)
FROM sales
GROUP BY category;エラーメッセージ
column "sales.product" must appear in the GROUP BY clause or be used in an aggregate function解決策
- GROUP BY句に
product列を追加する - もしくは、
product列に集計関数を適用する
修正後のクエリ例
SELECT category, MAX(product) AS sample_product, SUM(amount)
FROM sales
GROUP BY category;NULLの扱い
GROUP BY句は、NULL 値を持つ行もグループ化します。NULL 値は同一とみなされ、1つのグループにまとめられます。
サンプルデータ
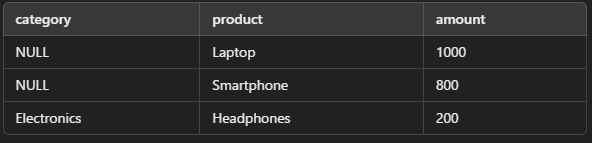
クエリ例
SELECT category, COUNT(*) AS count
FROM sales
GROUP BY category;実行結果

NULL値が存在する場合の挙動を考慮し、結果を適切に解釈する必要があります。
GROUP BY句によるパフォーマンスへの影響
GROUP BY句を使用すると、データのグループ化と集計が行われるため、大量のデータセットに対して実行するとパフォーマンスに影響を及ぼす可能性があります。
改善方法
- 必要に応じてインデックスを追加する(特にGROUP BYに使用する列)
- クエリを分割して処理を簡略化する
- PostgreSQLの
EXPLAINやANALYZEを使用してクエリの実行計画を確認し、ボトルネックを特定する
まとめ
GROUP BY句は、PostgreSQLを使用したデータ分析や集計において欠かせない機能です。本記事では、GROUP BY句の基本的な使い方から応用的な活用方法、そして注意すべきポイントまでを解説しました。
GROUP BY句を理解し、正しく活用することで、PostgreSQLを使ったデータベース操作の幅が大きく広がります。基本をしっかり押さえつつ、実践的なシナリオで使いこなしていきましょう。
あなたのデータ分析や業務でGROUP BY句を活用するヒントになれば幸いです!
PostgreSQLは、現場でも広く使われている信頼性の高いデータベースです。もしこれから本格的に学び、実務で通用する力をつけたい方には、RareTECHをチェックしてみてください。実案件ベースのカリキュラムで、あなたのスキルを次のステージへ引き上げてくれるはずです。
 なんくる
なんくる「本当にエンジニアとしてやっていけるか不安…」という方も、実践的な開発に関わることで、転職後の働き方を事前に体感できますよ。
実務で使えるDBスキルとともに、プログラミングスキルをちゃんと身につけたいなら、
RareTECHの無料カウンセリングで、学ぶ目的やゴールをプロと一緒に明確にしてみましょう。独学では得られない「実践的な成長の道筋」が見えてきます。

もしこの内容を通して、PostgreSQLについてさらに理解を深めたいと感じられたなら、信頼できる講座や書籍を紹介した別記事をご覧いただくのも良いかと思います。ご自身の学びに、きっとお役立ていただけるはずです。









コメント